Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM

Well, once I hit over 4300 bookmarks, I decided it was time to write a script that would get me some bookmark stats (such as folders, number per folder, duplicates, etc.).
When I initially set out, I wanted to figure out what information I could get from a browser HTML export that would be useful (as well as how to display it).
import collections
import cProfile
import re
import requests
from bs4 import BeautifulSoup
# http://www.quesucede.com/page/show/id/python-3-tree-implementation
class Node:
def __init__(self, identifier, parent=None):
self.__identifier = identifier
self.__children = []
self.__parent = parent
@property
def identifier(self):
return self.__identifier
@property
def children(self):
return self.__children
@property
def parent(self):
return self.__parent
def add_child(self, identifier):
self.__children.append(identifier)
class Tree:
def __init__(self):
self.__nodes = {}
@property
def nodes(self):
return self.__nodes
def add_node(self, identifier, parent=None):
if parent is not None:
node = Node(identifier, self.__nodes[parent])
else:
node = Node(identifier)
self[identifier] = node
if parent is not None:
self[parent].add_child(identifier)
return node
def display(self, identifier, depth=0):
children = self[identifier].children
if depth == 0:
print identifier
else:
print "\t" * depth + str(identifier)
depth += 1
for child in children:
self.display(child, depth) # recursive call
def traverse(self, identifier, mode="depth"):
# Python generator. Loosly[sic] based on an algorithm from
# 'Essential LISP' by John R. Anderson, Albert T. Corbett,
# and Brian J. Reiser, page 239-241
yield self.__nodes[identifier]
queue = self[identifier].children
while queue:
yield self.__nodes[queue[0]]
expansion = self[queue[0]].children
if mode == "depth":
queue = expansion + queue[1:] # dfs
elif mode == "breadth":
queue = queue[1:] + expansion # bfs
def __getitem__(self, key):
return self.__nodes[key]
def __setitem__(self, key, item):
self.__nodes[key] = item
def createSoup(browser):
with open ("./bookmarks_" + browser + ".html", "r") as myfile:
html = myfile.read()
soup = BeautifulSoup(html, 'html.parser')
return soup
def getChildren(theNode, level):
children = []
theChildren = theNode.findAll('dl')
for child in theChildren:
parents = len(child.findParents('dl'))
header = child.findPrevious('h3')
if parents == level + 1:
children.append(str(''.join(header.findAll(text=True))))
return children
def genHeaderTree(browser, theSoup):
iterSoup = theSoup.findAll('dl')
if browser == "chrome" or browser == "firefox":
headerList = theSoup.findAll('h3')
iterSoup = iterSoup[1:]
else:
headerList = theSoup.findAll(re.compile("h?"))
firstHeader = str(headerList[0].text)
headerTree = Tree()
headerTree.add_node(firstHeader)
for item in iterSoup:
parents = len(item.findParents('dl'))
children = getChildren(item, parents)
if children:
for child in children:
if browser == "chrome" or browser == "firefox":
parent = str(item.findPrevious('h3').text)
else:
parent = str(item.findPrevious(re.compile("h?")).text)
headerTree.add_node(child, parent)
return headerTree
def printHeaderList(browser, theTree, theSoup, linkList):
if browser == "chrome" or browser == "firefox":
headerList = theSoup.findAll('h3')
else:
headerList = theSoup.findAll(re.compile("h?"))
firstHeader = ''.join(headerList[0].findAll(text=True))
iterTree = theTree.traverse(firstHeader, "depth")
removed = 0
if browser == "chrome" or browser == "firefox" or browser == "ie":
next(iterTree) # Remove "Bookmarks Toolbar" or "Bookmarks"
removed += 1
for node in iterTree:
temp = node
parents = 0
while temp.parent:
parents += 1
temp = temp.parent
prepend = "\t" * (parents - removed)
links = getLinks(browser, theSoup, node.identifier)
count = len(links)
percentage = "{0:.2f}%".format(((count + 0.0)/len(linkList)) * 100)
print (prepend + str(node.identifier) + " - " +
str(count) + " = " +percentage)
def getLinks(browser, theSoup, header):
s = None
# Total time: 2.00404 s - slowest part of the code
headerNodes = theSoup.findAll('h3')
for node in headerNodes:
if node.text == header:
s = node
break
while getattr(s, 'name', None) != 'dl':
if browser == "chrome" or browser == "ie":
s = s.nextSibling
elif browser == "firefox":
s = s.findNext('dl')
return s.findAll('a')
def populateList(linkList, urlType):
urlList = []
for link in linkList:
if urlType == "normal":
urlList.append(str(link['href']))
elif urlType == "noProtocol":
noProtocol = link['href'].split('://', 1)[-1]
urlList.append(str(noProtocol))
return urlList
def getDupes(inList):
return [item for item, c in collections.Counter(inList).items() if c > 1]
def checkStatus(link):
resp = requests.head(link)
return resp
def main():
supportedBrowsers = ["chrome", "firefox", "ie"]
browser = "chrome"
getCount = True
checkDupes = True
checkErrors = False
mySoup = createSoup(browser)
linkList = mySoup.find_all('a')
# Firefox only fix
for link in linkList[:]:
if link['href'].startswith('place'):
linkList.remove(link)
myTree = genHeaderTree(browser, mySoup)
if getCount:
total = len(linkList)
print "Total number of bookmarks: " + str(total) + "\n"
if checkDupes:
if any(browser in s for s in supportedBrowsers):
printHeaderList(browser, myTree, mySoup, linkList)
urlList = populateList(linkList, "normal")
dupes = getDupes(urlList)
print "\n\nDUPLICATE LINKS = " + str(len(dupes))
print "----------------"
for dupe in dupes:
print dupe
urlList = populateList(linkList, "noProtocol")
dupes = getDupes(urlList)
print "\nDUPLICATE LINKS (IGNORING PROTOCOL) = " + str(len(dupes))
print "------------------------------------"
for dupe in dupes:
print dupe
if checkErrors:
print "\nERROR CONNECTS"
print "---------------"
for link in linkList:
try:
response = checkStatus(link['href'])
except:
print "ERROR?!"
if response.status_code != 200:
print str(response.status_code) + " - " + link['href']
if __name__=="__main__":
main()
The script had to not only my total number of bookmarks, but also how many bookmarks I had in each folder (and sub-folders). This was not in any of the applications or plugins that I could find, but BookmarkStats does just that.
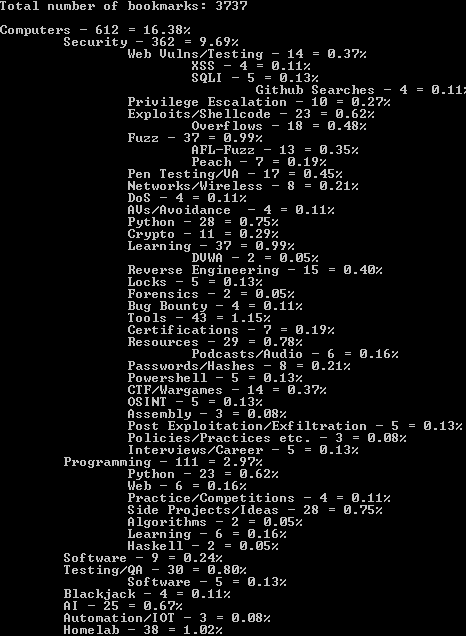
Additionally, I wanted duplicate checking in the same application, with some wiggle room. For now I have implemented ignoring the protocol (as I had some “dupes” that were normally ignored because they were HTTP vs HTTPS). In the future, I also plan on adding almost duplicates (maybe the URL slightly changed, or it is a similar URL to the same page).

I plan on adding support for more browsers, as well as some visualizations and even timeout checking in the future. That said, even for now this script has helped me drop down to 3508 bookmarks and counting!
As usual, the code and updates can always be found in my GitHub repository as well.
Ray Doyle is an avid pentester/security enthusiast/beer connoisseur who has worked in IT for almost 16 years now. From building machines and the software on them, to breaking into them and tearing it all down; he’s done it all. To show for it, he has obtained an OSCE, OSCP, eCPPT, GXPN, eWPT, eWPTX, SLAE, eMAPT, Security+, ICAgile CP, ITIL v3 Foundation, and even a sabermetrics certification!
He currently serves as a Senior Staff Adversarial Engineer for Avalara, and his previous position was a Principal Penetration Testing Consultant for Secureworks.
This page contains links to products that I may receive compensation from at no additional cost to you. View my Affiliate Disclosure page here. As an Amazon Associate, I earn from qualifying purchases.


