Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM
Address
304 North Cardinal St.
Dorchester Center, MA 02124
Work Hours
Monday to Friday: 7AM - 7PM
Weekend: 10AM - 5PM

While not exactly security related, I’ve had to do some Python dotx conversion to docx files recently.
I’ve been working on a tool (coming soon?) for automating the my pentest engagement organization.
Part of this tool required me to copy over a .dotx template and save it as a .docx file. The reason for this is that our report templates are .dotx by default, but I wanted to start with a blank .docx for each engagement.
First, I installed python-docx.
Rays-MBP:tools doyler$ pip install python-docx
Collecting python-docx
Downloading python-docx-0.8.6.tar.gz (5.3MB)
100% |�-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-��-�| 5.3MB 26kB/s
Requirement already satisfied: lxml>=2.3.2 in /usr/local/lib/python2.7/site-packages (from python-docx)
Building wheels for collected packages: python-docx
Running setup.py bdist_wheel for python-docx ... done
Stored in directory: /Users/doyler/Library/Caches/pip/wheels/cc/74/10/42b00d7d6a64cf21f194bfef9b94150009ada880f13c5b2ad3
Successfully built python-docx
Installing collected packages: python-docx
Successfully installed python-docx-0.8.6
With this installed, I figured I’d be able to go about implementing it in my script. Unfortunately, python-docx does not yet support dotx files out of the box.
Based on the above GitHub issue, I needed to make a few simple changes to support dotx files.
First, I added the proper content types to api.py. I added macro enabled templates as well, just in case.
Rays-MBP:__ENGAGEMENTS doyler$ vi /usr/local/lib/python2.7/site-packages/docx/api.py
...
def Document(docx=None):
"""
Return a |Document| object loaded from *docx*, where *docx* can be
either a path to a ``.docx`` file (a string) or a file-like object. If
*docx* is missing or ``None``, the built-in default document "template"
is loaded.
"""
docx = _default_docx_path() if docx is None else docx
document_part = Package.open(docx).main_document_part
if document_part.content_type != CT.WML_DOCUMENT_MAIN:
tmpl = "file '%s' is not a Word file, content type is '%s'"
raise ValueError(tmpl % (docx, document_part.content_type))
return document_part.document
if document_part.content_type not in [CT.WML_DOCUMENT_MAIN, 'application/vnd.openxmlformats-officedocument.wordprocessingml.template.main+xml', 'application/vnd.ms-word.document.macroEnabled.main+xml']:
Next, I added the DocumentPart for these content types to the PartFactory in init.
Rays-MBP:__ENGAGEMENTS doyler$ vi /usr/local/lib/python2.7/site-packages/docx/__init__.py ... PartFactory.part_type_for[CT.WML_DOCUMENT_MAIN] = DocumentPart PartFactory.part_type_for[CT.WML_DOCUMENT_MAIN] = DocumentPart PartFactory.part_type_for['application/vnd.openxmlformats-officedocument.wordprocessingml.template.main+xml'] = DocumentPart PartFactory.part_type_for['application/vnd.ms-word.document.macroEnabled.main+xml'] = DocumentPart
With the monkey-patches in place, it was time to write the script to create my document.
This is a very simple excerpt, but it opens my template, sets the content type, and saves the file with the new extension.
from docx import Document
from docx.opc.constants import CONTENT_TYPE as CT
document = Document('appsec/web_application_assessment_report.dotx')
document_part = document.part
document_part._content_type = CT.WML_DOCUMENT_MAIN
document.save('/Users/doyler/Documents/__ENGAGEMENTS/__DEMO.docx')
Rays-MBP:__ENGAGEMENTS doyler$ file __DEMO.docx __DEMO.docx: Microsoft OOXML
While it isn’t a huge deal to convert from dotx to docx, that code snippet is making my life easier for now.
It is still not quite ready for release, but here is a screenshot of the output for my newEngagement script.
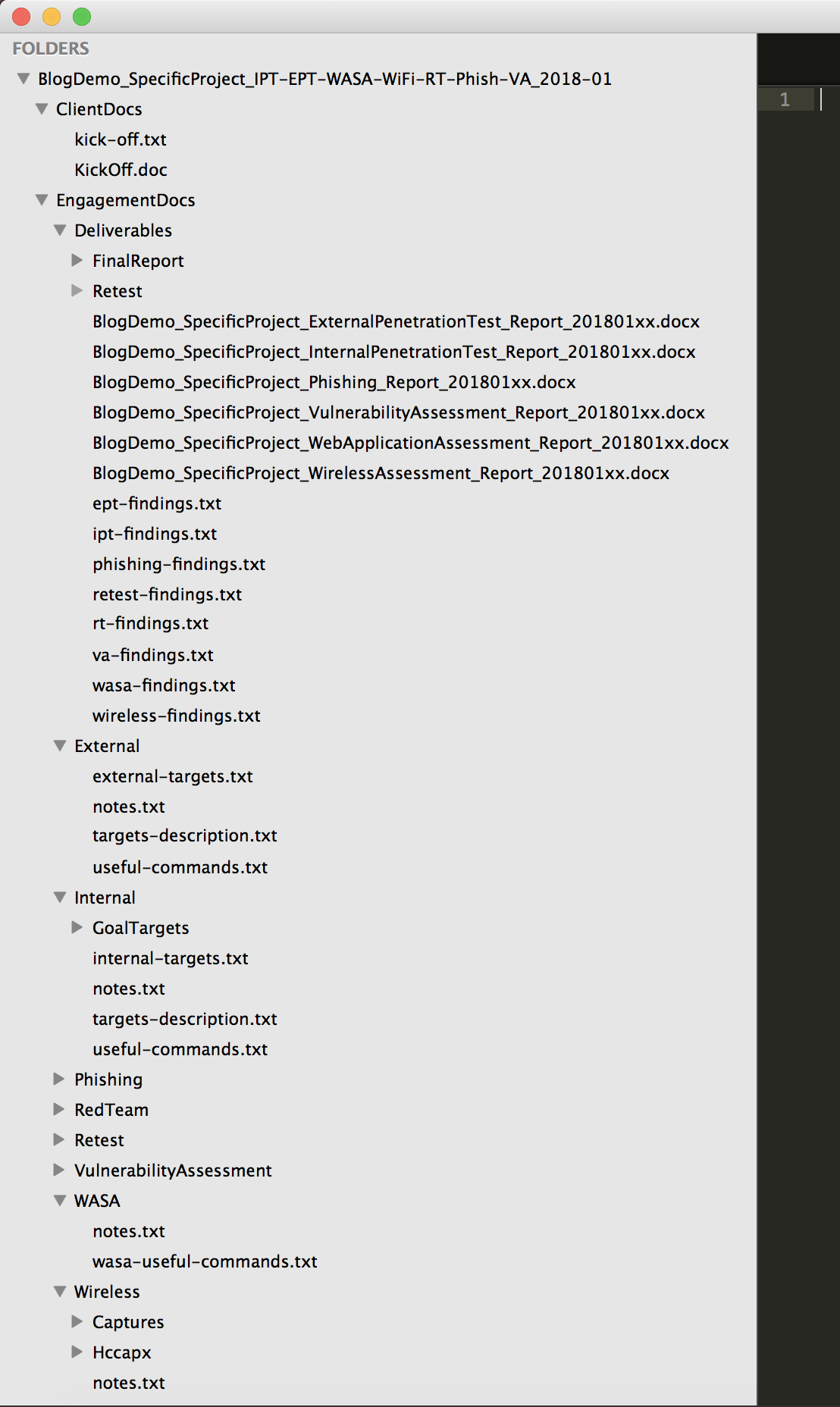
Let me know if you have any ideas or suggestions before I release it! Note that it is still geared towards my specific uses, but is easily modifiable.
Ray Doyle is an avid pentester/security enthusiast/beer connoisseur who has worked in IT for almost 16 years now. From building machines and the software on them, to breaking into them and tearing it all down; he’s done it all. To show for it, he has obtained an OSCE, OSCP, eCPPT, GXPN, eWPT, eWPTX, SLAE, eMAPT, Security+, ICAgile CP, ITIL v3 Foundation, and even a sabermetrics certification!
He currently serves as a Senior Staff Adversarial Engineer for Avalara, and his previous position was a Principal Penetration Testing Consultant for Secureworks.
This page contains links to products that I may receive compensation from at no additional cost to you. View my Affiliate Disclosure page here. As an Amazon Associate, I earn from qualifying purchases.



I tried this except I tried to convert a .docx to a .dotx. Not working for me (corrupts file) – do you know if there’s a way I can get it to work?
Hi Hunter,
As far as the other direction, you’d have to reverse the content type from main to application/vnd.openxmlformats-officedocument.wordprocessingml.template.main+xml
Has this update been released? Trying to convert .dotx and getting the error
ValueError: file ‘test-outpufft.dotx’ is not a Word file, content type is ‘application/vnd.openxmlformats-officedocument.wordprocessingml.template.main+xml’
No, there has been no updates released for the library itself.
You’ll have to manually update the two files yourself like I mentioned in the post. Let me know if that makes sense or if you have any questions/issues.
I’m getting an error in api.py:
def _default_docx_path():
^
IndentationError: expected an indented block
I’m thinking it’s because of the if statement at the bottom of your first block of code. Here’s what I have in my api.py file:
def Document(docx=None):
“””
Return a |Document| object loaded from *docx*, where *docx* can be
either a path to a “.docx“ file (a string) or a file-like object. If
*docx* is missing or “None“, the built-in default document “template”
is loaded.
“””
docx = _default_docx_path() if docx is None else docx
document_part = Package.open(docx).main_document_part
if document_part.content_type != CT.WML_DOCUMENT_MAIN:
tmpl = “file ‘%s’ is not a Word file, content type is ‘%s'”
raise ValueError(tmpl % (docx, document_part.content_type))
return document_part.document
if document_part.content_type not in [CT.WML_DOCUMENT_MAIN, ‘application/vnd.openxmlformats-officedocument.wordprocessingml.template.main+xml’, ‘application/vnd.ms-word.document.macroEnabled.main+xml’]:
def _default_docx_path():
“””
Return the path to the built-in default .docx package.
“””
_thisdir = os.path.split(__file__)[0]
return os.path.join(_thisdir, ‘templates’, ‘default.docx’)
What am I doing wrong here? Thanks
If you are copying and pasting directly from my post, then make sure the spacing/lines are ending up correct.
That line that begins with if should encompass EVERYTHING until the colon. It looks like you have a spacing/indentation issue somewhere in your code.
It does. The whole if statement up until and including the colon is on one line. The issue is that there’s nothing inside the if statement, so when it gets to def_default_docx_path(): , it sees that it’s not indented ( it expects an indentation since we just did if […]: ). Is there something that’s supposed to be in the if statement?
The if statement should be what was modified, and the body of that statement should stay the same in the original file.
I’ve only posted my modifications, not the file in its entirety.
Hey I just wanted to let you know that I got it to work and it does in fact convert .docx to .dotx. Thanks so much for your help!
Awesome, great to hear and glad to help!
Have you considered trying to submit a pull request to github.com/python-openxml/python-docx ? I tried to but I honestly don’t know what I’m doing, and it didn’t get accepted.